Overview
Technical Foundations
ZDMP is a wide platform which integrates several technologies to achieve the zero defects in the manufacturing industry. Technically speaking, the foundations of the platform are based in the next principles:
- Container first. Each component of ZDMP is designed and developed to be executed inside Docker containers. This is the base to allow several features like scalability, composability as well as the use of different technologies across the platform
- Extensibility. Each docker container, or at least those which have something to share, are wrapped in an API, and documented using OpenAPI specification. This allows the interoperability, opening the possibility to easily extend, or consume, the platform’s services.
- Distributed Architecture. Every component is designed to be executed in a distributed way. For that, ZDMP uses orchestration technologies like Docker Swarm and Kubernetes. This feature permits to run ZDMP in different ways, like on premises or as a SaaS in the cloud. Allows scalability also.
- Composability. ZDMP components are building blocks which can be composed in different manners. This is required, because the industry is heterogeneous and requires that the solutions be adaptable to their reality. For that reason, ZDMP’s components are composable through a service and message bus. In that way, every component can adapt itself to a specific instance of ZDMP.
- Secure. Security matters, and in an industry more. For that reason, ZDMP includes several security controls which includes: centralised authentication and authorisation, secure communications throught SSL, continously monitoring using an integrated SIEM and auditability of every action performed in the platform per user, for forensic purposes, and always satisfaying RGPD.
- Big Data and AI Driven. ZDMP provides infrastructure, tools and pipelines to support a wide catalog of AI models, which uses Big Data tools.
- Connectivity. Ready to connect with the most used industry protocols.
- Developer experience. ZDMP provides several tools to ease the development of new components.
- Extensible. Core functionalities can be extended purchasing new components in the marketplace.
- Interoperable. ZDMP can be connected to other platforms throught the API’s.
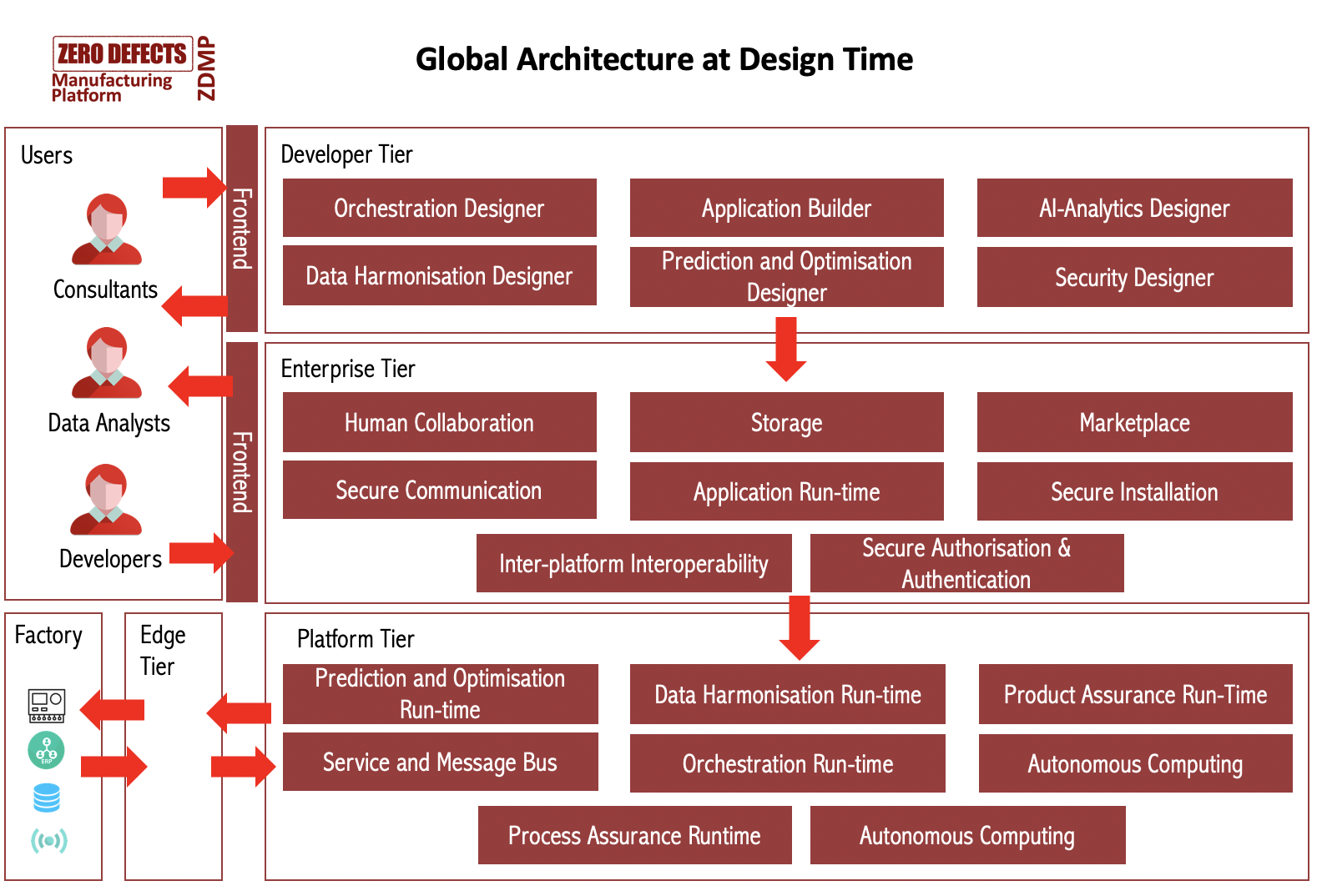
Architecture at Design Time
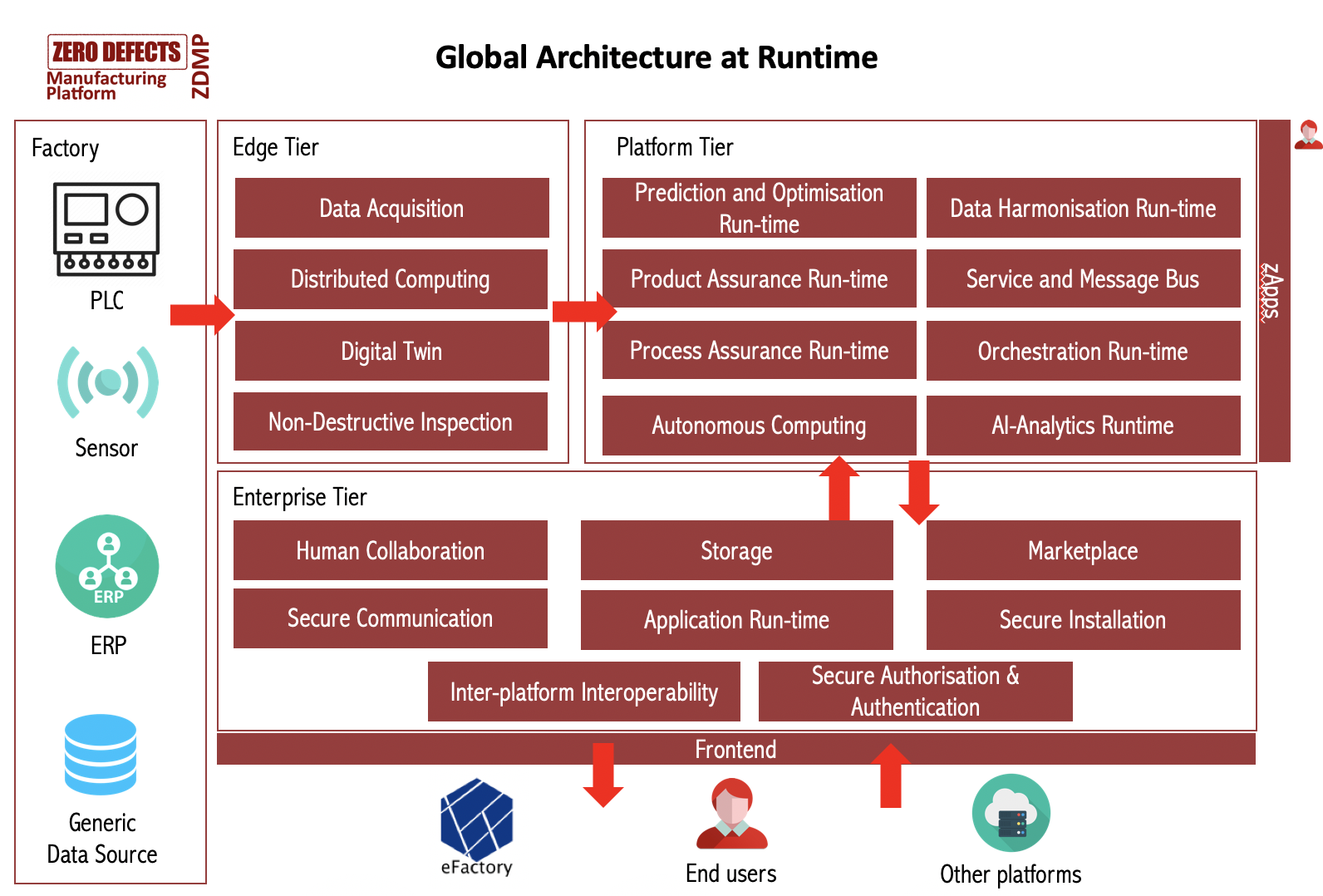
Architecture at Run Time
ZDMP’s Component Structure
ZDMP is a complex platform, which needs to integrate several components to work properly. On the one hand, the integration is of paramount importance at the initial phases of the development. To ensure, or at least to ease, that integration every component must follow a set of guidelines to fit in the overall ZDMP platform.
On the other hand, the software development process it is very wide, and it is not the intention to strictly guide developers in one and only way to carry out the development. The developer user experience is important, if development process is too complex, unclear or confusing, they will simply not use it.
So to accomplish that, ZDMP allows several ways to work with, but all of that ways have some commons activities and way of producing software that are described in the following subsections.
Commons
Every component repository must have the following mandatory structure:
---- documentation
---- public
---- img
---- openapi
README.md
---- orchestration
docker-compose.yml
In which:
- documentation –> public –> README.md
- Contains the public documentation which is automatically published using CI/CD pipelines
- documentation –> public –> img
- Contains the images used in README.md
- documentation –> public –> openapi
- Contains the Open API specifications of the component
- And these are published automatically in the online public documentation
- orchestration –> docker-compose.yml
- Contains the recipe to raise up the component in standalone mode automatically using docker-compose
Component orchestration
Every component has his own architecture, and every architecture is composed of several subsystems. Next figure shows an example of a specific architecture defined for a ZDMP component:
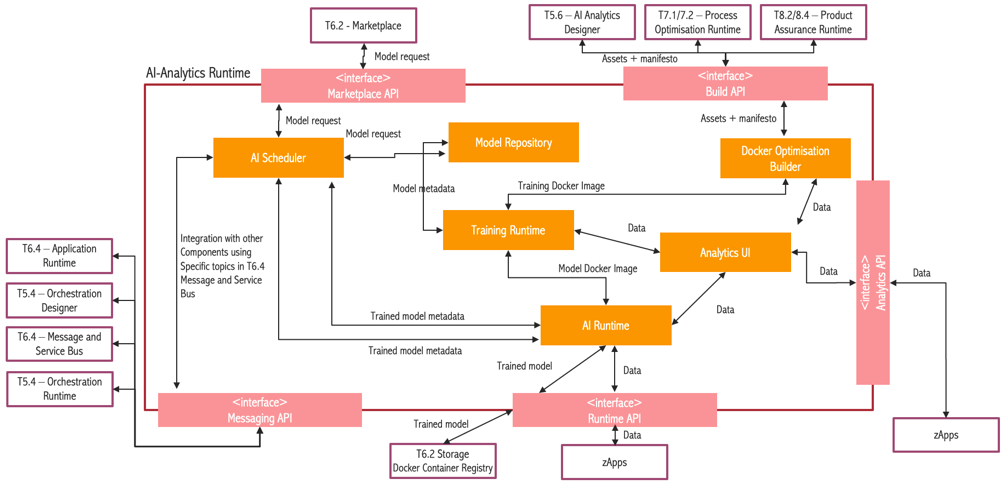
As shown in the example, component is formed by a set of subsystems. Those subsystems can be transformed in APIs, databases, frameworks, engines, etc. It is not important, from an integration perspective point of view, the technology used in the component. Developers are free to use the technology they think better accomplish their targets; so in this case the only requirement is that it must run in a docker container.
At the end, there is the need to orchestrate all those subsystems, connect them in some way, and run them easily, and it has to be done without the need of knowing specific technologies and implementations. Furthermore, all the things that are not code and the the subsystems to build a component will be configured using docker-compose. Of course, there may be exceptions. In fact, some of the components cannot be dockerized, because they may be e.g. desktop or mobile applications, As long as they are client applications that consume ZDMP services this is not an issue.
Every team of developers can build their own component orchestration in several ways, called flavor in the ZDMP terminology, it can be monorepository, multirepository, proprietary or mixed, and this is explained in the following subsections.
Monorepository flavor
One approach is to use a monorepository flavor. Here the developers put all the code of each subsystem in a folder. The standard folder name is called ‘subsystems’ in ZDMP, but this is only to ease the CI/CD tasks.

This approach has several benefits:
- Easy to set up a CI/CD pipeline. It is only needed to configure it in one place
- docker-compose.yml configuration directly over the code, avoiding the need to use another system (package managers, docker registries, external servers, etc.)
- All the team can have a look at the code, and know how works the subsystem
- Unified management: issues, milestones, and code are placed in the same repository
Of course, not all the deployments can fit in this flavor. Proprietary software code may not be uploaded, or simply the technical team may feel uncomfortable with this structure.
Multirepository flavor
Another approach is to use a set of repositories. In this case, and taking the example explained in the monorepository section Figure 8, it may be composed of:
- Four repositories, one per subsystem defined in the architecture (predictions-repository, product-quality-model-api, product-quality-trainer and quality-predictor)
- Self-organized:
- Freedom to choose the internal structure
- Freedom to choose technologies, stacks or whatever
- Result of the repository should be a docker image, and be stored in a docker registry
- Self-organized:
- The component official repository must follow:
- Commons structure
- Docker-compose.yml should link the docker image stored in the docker registry
In summary, the multirepository flavor approach should:
- Create as many repositories as the developer team needs, without restriction
- Build docker images for every subsystem and store them in a docker container registry
- Developers are free to use the container registry they want
- Maintain the docker-compose.yml in the orchestration folder, using the commons structure
- Docker-compose must link to docker registry instead of source code
Proprietary code or external repository flavor
In some cases, the component is composed of a set of subsystems, some of them proprietary that does not allow the source code to be stored in the ZDMP repository. This is the case were it is used the multirepository flavor.
Even for proprietary code, the component must be able to startup and be used in the ZDMP architecture. So, even in this situation, the developers are responsible to provide a properly built docker-compose.yml file.
Mixed flavor
Finally, all previous flavors can be mixed for a component if needed. It can be easily seen in the following example.
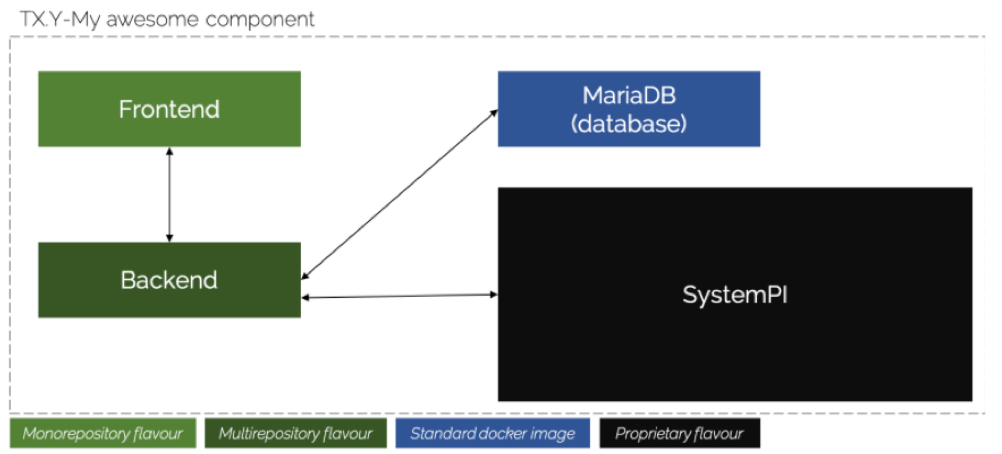
As we described above, the developers must fulfill the commons structure, which basically consists of:
---- documentation
---- public
---- img
---- openapi
README.md
---- orchestration
docker-compose.yml
Focusing on the monorepository flavor, represented by the frontend subsystem, a folder named subsystems should be created, and put the code of the frontend inside as depicted in the following figure.
It is important to remember that, from the orchestration perspective, the technology does not really matter. The key here is to define the integration of that subsystem in the overall architecture, using Docker and Docker Compose.
To integrate the frontend subsystem into Docker Compose, it is needed first to define the construction of the Docker image. This is achieved by the definition of a Dockerfile, which has the recipe to build the final image. That file should be in the subsystem folder, in this example, the frontend folder. An example of Dockerfile for the frontend subsystem is represented in the next image.
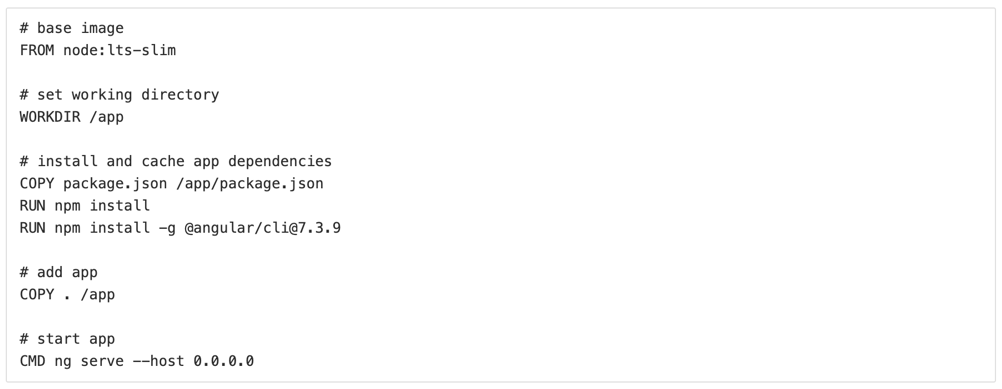
Dockerfile explains how a container is created, but does not explain how it is orchestrated. That is the mission of the docker-compose.yml, which retrieves the building information of the previous Dockerfile and starts up the subsystem easily, docker-compose.yml in next figure starts up the frontend subsystem described above.

Focusing on the backend, the multirepository flavour, the source code is on that subsystem also, but not in the same repository as the Docker Compose, for that reason the Docker Compose cannot be linked using the build tag.
How looks the repository, or what’s its structure, it’s irrelevant for the orchestration purpose. The only important thing is that the backend subsystem needs to generate a Docker image and upload it to an accessible Docker Registry, for example Docker Hub.
The developers can orchestrate the new backend in the docker compose file once the docker image is uploaded to a container registry. Next image shows an example of integration between frontend (monorepository) and backend (multirepository)

Actually, the multirepository flavor and the proprietary code flavor are basically the same.
Finally, when all the subsystems of the component are described in the docker-compose.yml file, the component may be started easily, merely executing the ‘docker-compose up’ command.
Platform orchestration
In this section the orchestration between components are tackled. The ZDMP platform can be delivered in several ways:
- As a SaaS in the cloud
- On Premise
The orchestration will vary, depending on the overlaying technologies of the systems in which ZDMP will be deployed. That means that the global integration of components is flexible. In any case, the architectural reference implementation relies on UNIX servers, and needs a Kubernetes cluster, in which the ZDMP components will be deployed using Helm charts, which is the standard packaging model for Kubernetes applications.
The foundations of Kubernetes are not far from the Docker Compose we defined in the previous section. Of course, the syntax varies, but the underlying concepts are the same. At this stage, the components are still in development, and for that reason we don’t have any example of integration using Kubernetes. Nevertheless, the components can integrate one each other using Docker Compose, and that is the approach followed in the project.
In the next stage of the project, once the components are more mature, the focus will be in the integration tasks. For the moment, some work has been carried out to the infrastructure needed to deploy the reference implementation of ZDMP.