Distributed Computing
General description
The Distributed Computing component is responsible for executing computing tasks (eg, API calls to Docker setups to change the number of resources used) and distributes the intensive computing work tasks through a cluster, composed by a group of work nodes. So, computing performance is improved by splitting large tasks into smaller ones, reducing overall processing time. Finally, the results of intensive computing work tasks coming from different nodes are recombined and structured in the Manager node as the expected result type from the main task (API Call), returning to the requesting component.
The Component also uses a Resource location mapper, whose intention is to provide the physical location of each computational resource in the cluster. This location is then passed as one or more Tags to the execution of a task, which is then used as a delimitation on where the task may be executed.
| Resource | Location |
|---|---|
| Source Code | Link |
| Online Documentation | Link |
| X Open API Spec | Link |
| Video | Link |
| Further Guidance | None |
| Related Datasets | None |
| Additional Links | None |
Screenshots
The following images are illustrative screen shots of the component:
Component Author(s)
| Company Name | ZDMP Acronym | Website | Logo |
|---|---|---|---|
| Ascora GmbH | ASC | www.ascora.de |  |
Commercial Information
| Resource | Location |
|---|---|
| IPR Link | Distributed computing component |
| Marketplace link | https://marketplace-zdmp.platform.zdmp.eu/63a1cedd3da47 |
Architecture Diagram
The following diagram shows the position of this component in the ZDMP architecture
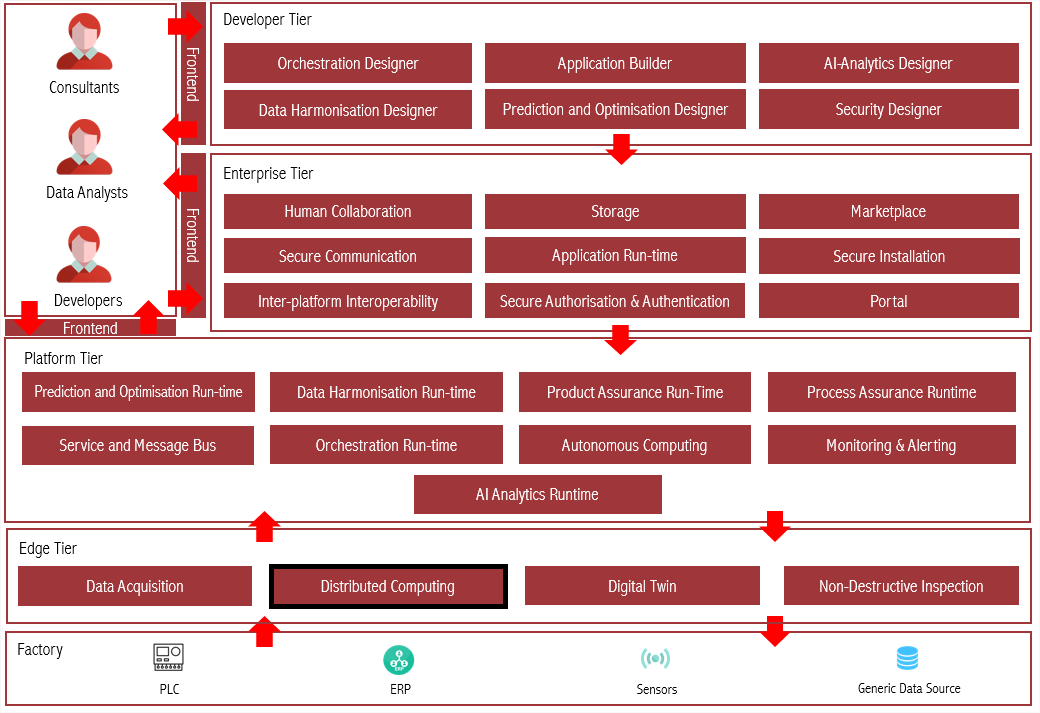
Figure 12: Architecture Diagram
Benefits
The primary benefits are:
Facilitates creation of logical structure for location of computational devices which can be used in efficient distribution of computational tasks at either Edge, Fog, or Cloud level
Distribute computational task as per location constraints
Central orchestration for computational resources in different locations
Separating computing resources against each other to get more security
Central overview of resources and workloads
Features
The Distributed Computing component offers the following features:
Registering multiple Kubernetes clusters
Deploying applications to the different clusters
Deploy to specific nodes or nodes groups with tags
Available cluster resources
Integration with ZDMP Core components
Overview of deployed tasks with an endpoint to access it
Create Location
Allow the creation of a locations structure representing the physical structure of factories and other buildings. Each location can have sub-locations.
Create Computational Resource
Allow the creation of computational resources representing physical or virtual machines located within the physical location previously defined. These resources are distributed and orchestrated by the controller.
Distributed Computing with locational constraints
Allows the execution of tasks in a distributive way, also allows the definition of the environment of execution, such as Fog, Edge based on the location, or the computational resources defined. Locations can be assigned to cluster with tags and labels. The cluster nodes can be assigned to sub-locations also with tags and labels.
System Requirements
The Distributed Computing has the following requirements:
Hardware Requirements
2 CPUs
8GB RAM
64GB disk space
Software Requirements
Docker
Rancher Server (2.4.x)
Kubernetes Cluster:
The cluster can be a k3s or a normal k8s cluster
The nodes must be able to reach the rancher server over the network
Associated ZDMP services
Required
Installation via Docker Compose
The Distributed Computing component can be installed via docker-compose, for this a server is also needed for the email credentials:
Download the latest docker-compose file from ZDMP’s HCE GitLab
Add the environment variable values. Choose the way to do it following the instructions from docker: https://docs.docker.com/compose/environment-variables/.
As an example, create a file named ‘.env’ in the same folder of the docker-compose file, with the following information:
MONGO_INITDB_SERVER=DateBaseServer
MONGO_INITDB_DATABASE=DataBaseName
MONGO_INITDB_ROOT_USERNAME=yourDataBaseUserName
MONGO_INITDB_ROOT_PASSWORD=yourDataBasePassword
- Install and start the component by executing the following command:
docker-compose up -d
Installation via miniZDMP
To install the Distributed Computing component on a miniZDMP instance, some preliminary work is necessary. To follow this guide, we assume that the installation and setup of the miniZDMP platform has been completed. Instructions on how to do this can be found here (https://gitlab-zdmp.platform.zdmp.eu/enterprise-tier/t6.4-application-run-time/-/tree/master/minizdmp or D087 Platform Integration and Federation).
For the component to be used, the following things must be ready to use:
Rancher Instance that can be managed
- Please login into your Rancher Instance and navigate to the Apps Section.
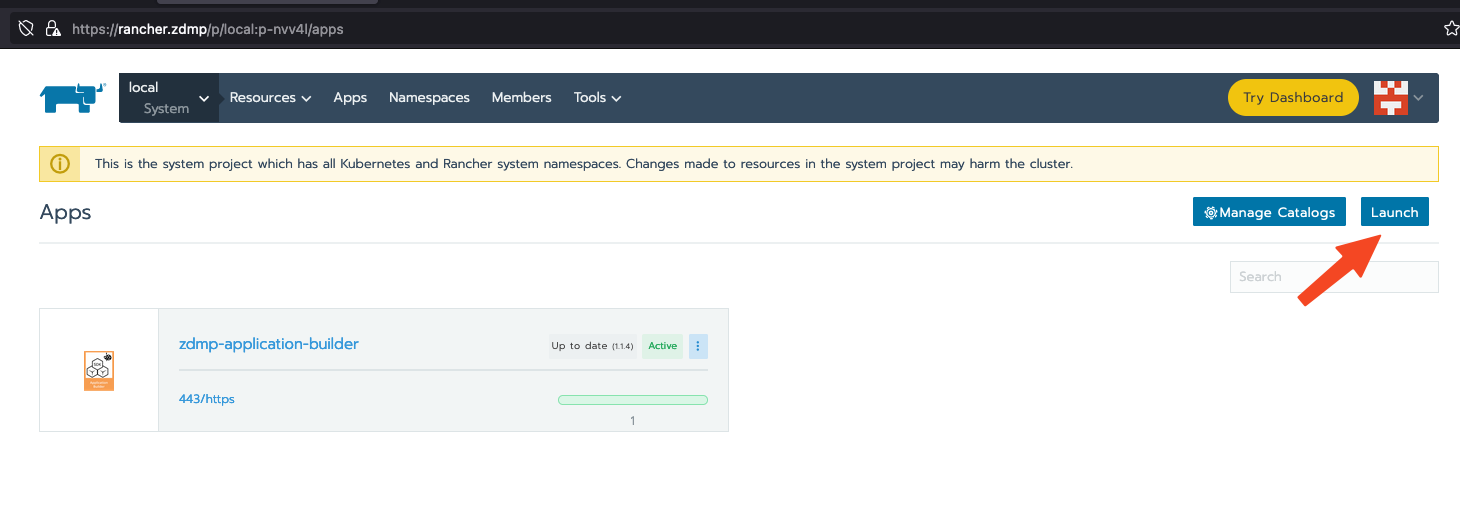
Figure 13 - Rancher Lunch an App
Please click on the Lunch Button to launch a new Application on the miniZDMP Kubernetes Cluster
Search for the Entry of “Distributed Computing / zdmp-distributed-computing” and click on it.
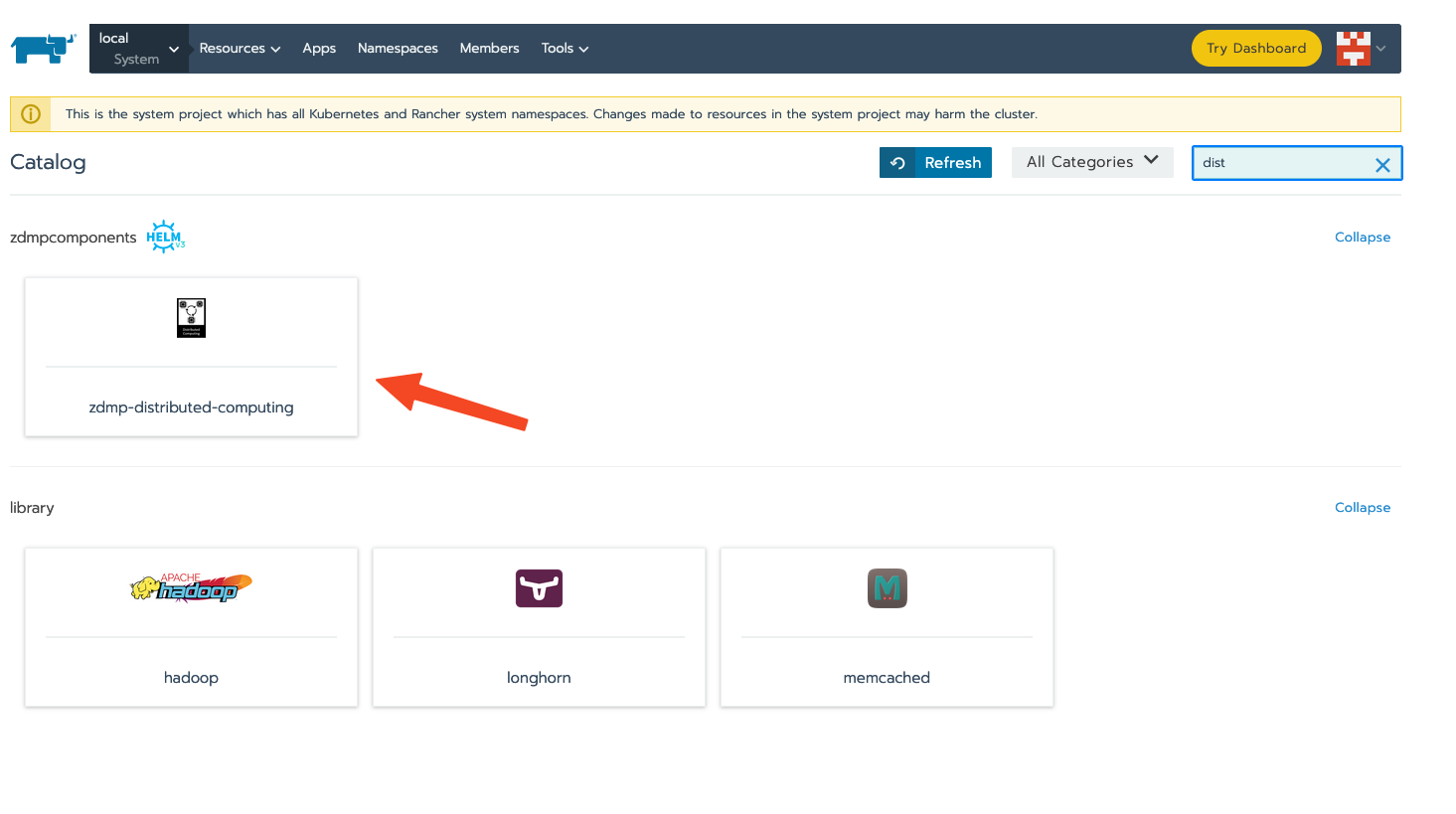
Figure 14 - Lunch the Distributed Computing App
In this step there are a few configurations needed, please set it to your needs.
Storage Type
Please set it to LOCAL or NFS. For NFS it is needed that you configure an NFS-Server in your miniZDMP Platform. Local means that the Data that are collected in this component will be saved to the local Server disk. In case of a NFS the data can be saved to Network Shared Directory (recommended way, prevents data loss).Domain Settings
You can adjust here the domain name, where this component will be available. The default is set to zdmp.home which is also a default of the miniZDMP Platform.
- Private Registry Settings
These settings are necessary to download the container of registry of ZDMP. For the HCE Gitlab please use your own credentials as username and password.
- Database
You need to provide data credentials for a mongodb Database.
- Environment Vars
Here it is possible to adapt the URLs in order to call up either other components or internal components. In a standard installation of miniZDMP, no changes should be necessary here.
How to use
The Distributed Computing component can be used through an API or a user interface.
API
Please refer to http://localhost:28021/api or https://distributed-computing-backend-zdmp.zdmp.home/api for the Swagger instructions on how to use the API. There can be found all the possible requests the component accepts, and its expected parameters or body content. The API can be accessed in http://localhost:28021/ or https://distributed-computing-backend-zdmp.zdmp.home (miniZDMP)
User Interface (UI)
Access http://localhost:28022 or https://distributed-computing-zdmp.zdmp.home (miniZDMP) to access the user interface.
Location
The location is a way to identify the physical structure of the factory, company or any other building needed. Using these locations, the user may define Computational resources where tasks may be executed. Computation of tasks can be guided to be executed within a specific room or computer (locations), also applying computation on Edge level.
To create a resource location the following is needed:
- Location Description: This property is used by the user to identify the Location. An Id is automatically generated
Follows a UI example with the creation of a Location:
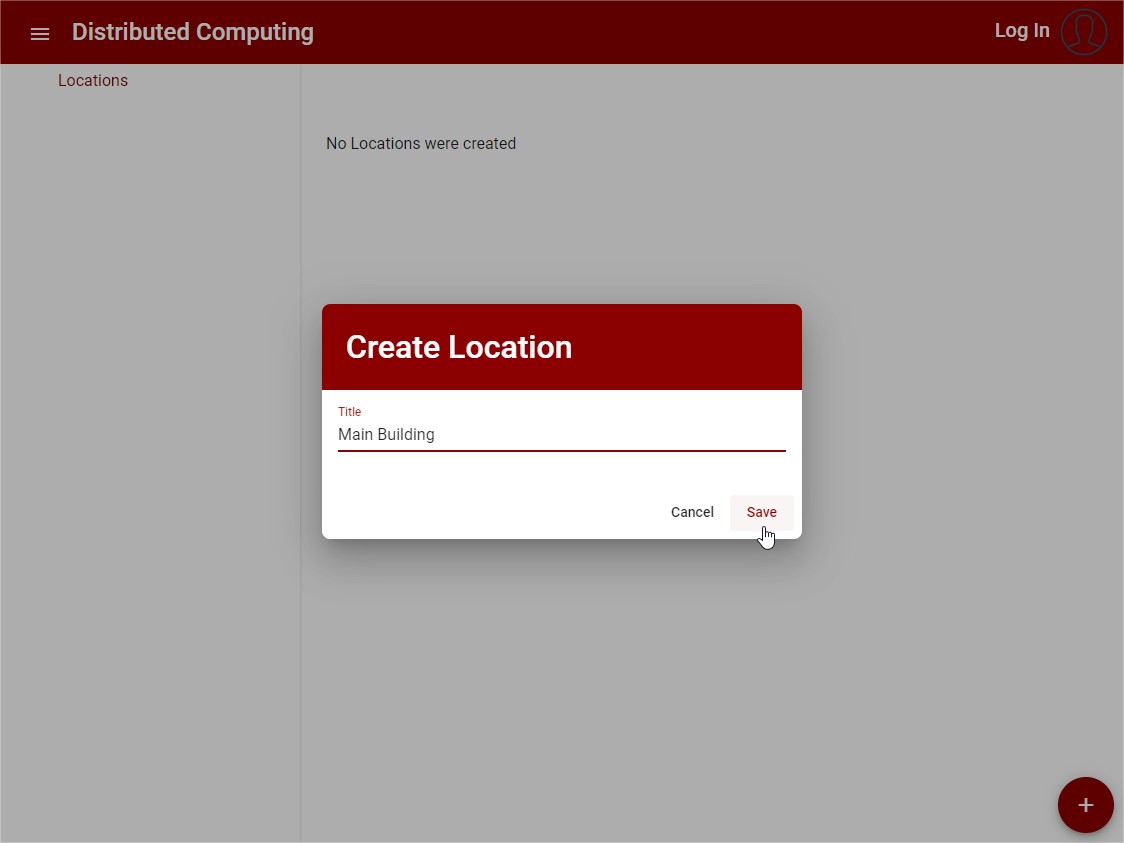
Figure 15: Create New Location
After the Location is created, it can be used to add other Locations or a computational resource.
Follows a UI example with the view of a Location with Computational resource and an inner location:
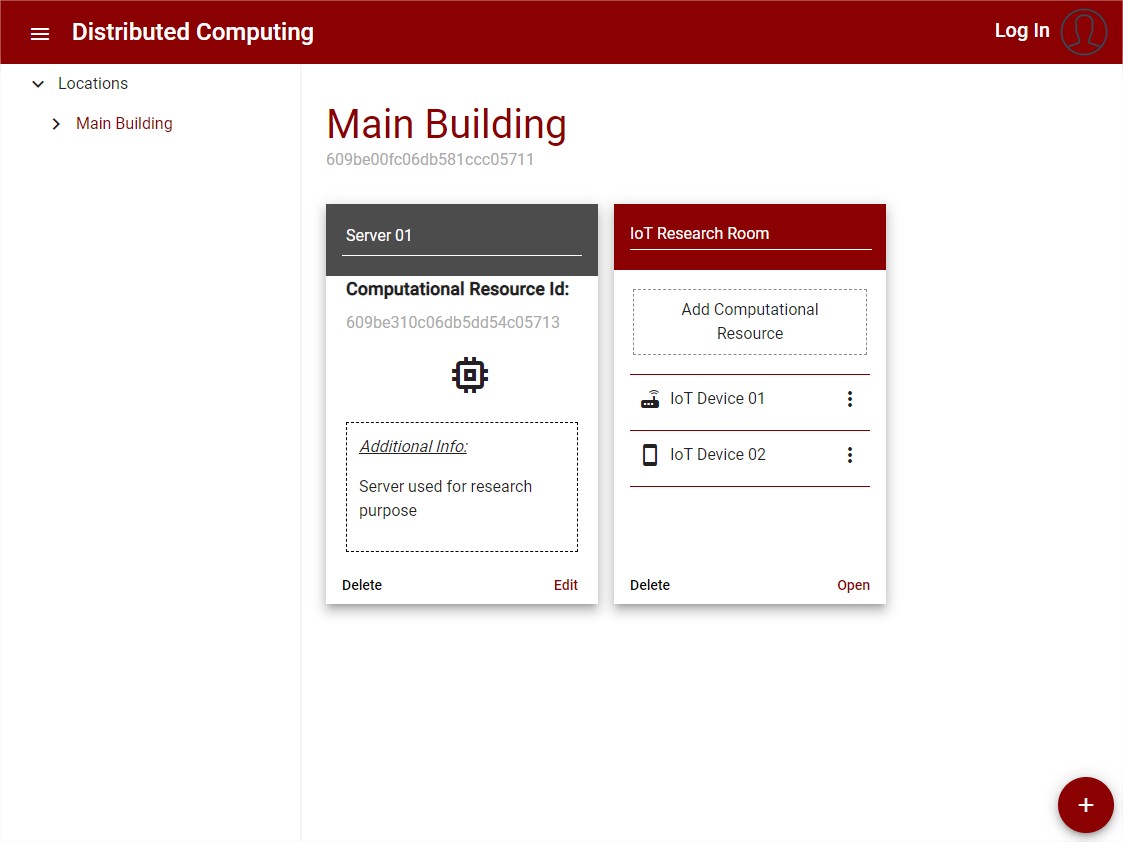
Figure 16: Resource’s List View
For the integration with the security designer, the UI and the data structure for the Resource Location is Updated to contain more information about the network of resources and the connection between them.
Computational Resource
The computational resource is a machine, device, or any other mechanism able to execute computational tasks, these resources are used to identify and allocate tasks to be executed in edge level.
To create a computational resource the following is needed:
Title: This property is used by the user to identify the Computational Resource. An Id is automatically generated
Icon: The icon is used as a visual attributed to help identify the type of computational resource, it is an optional field
Additional Information: This field can be used for the user to add any information related to the computational resource necessary, it is an optional field
Follows a UI example with the creation of a computational resource:
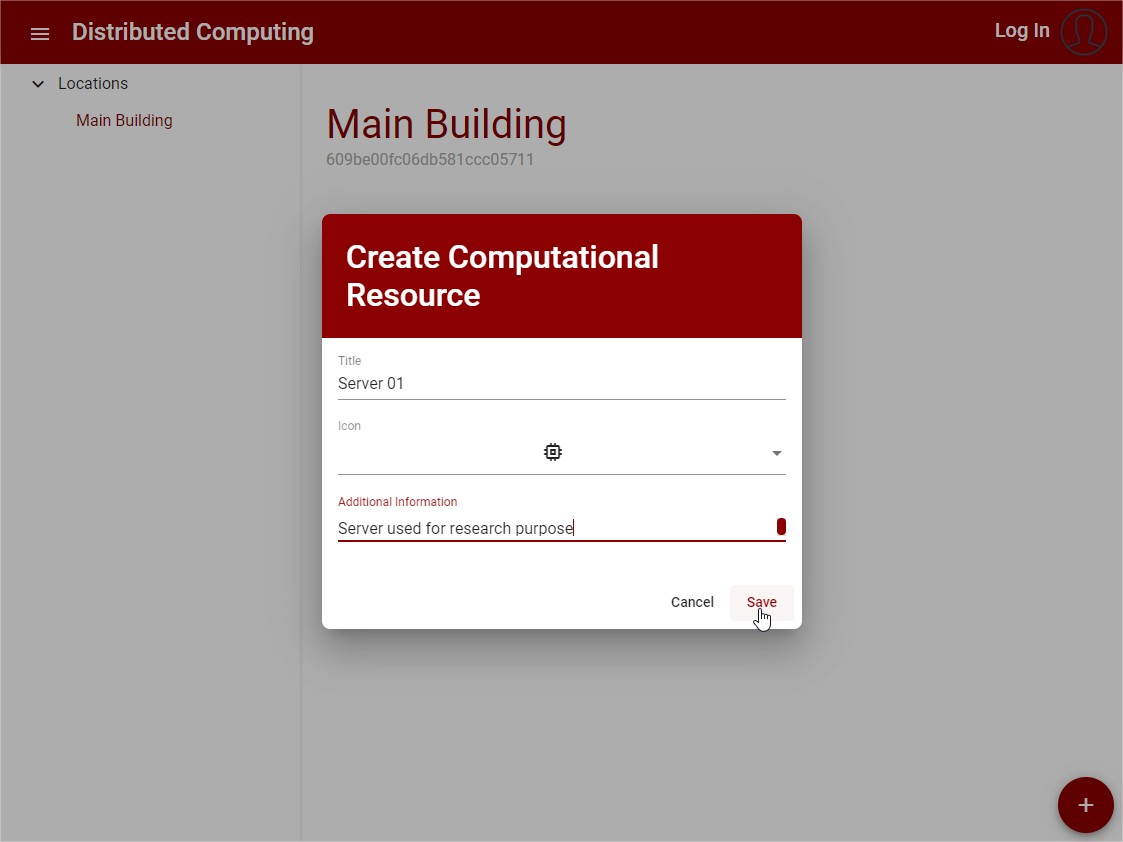
Figure 17: Create Computational Resource
After the Location is created, it can be used to add other Locations or a computational resource.
Cluster
The user can use Distributed computing UI to create clusters and deploy applications to the Edge environment.
To create a cluster the following is needed:
Name: The name that identifies the cluster
Annotations: Annotations to attach to the cluster, composed of key and value, it is an optional field
Labels: Labels to attach to the cluster, composed of key and value, it is an optional field
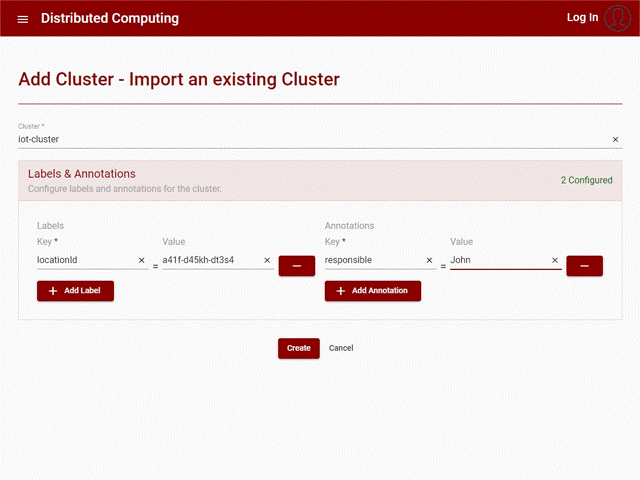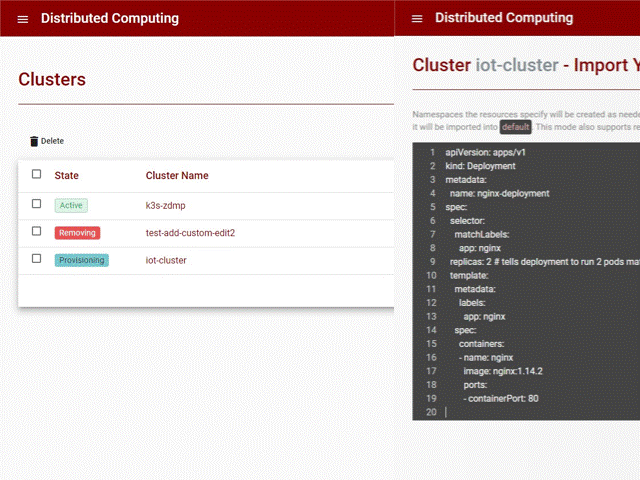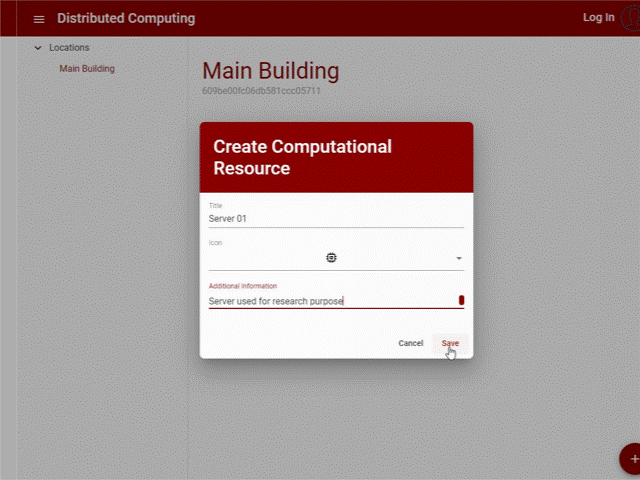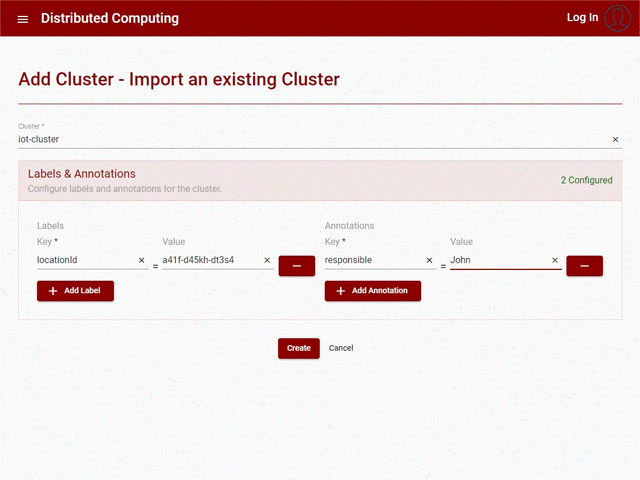
Follows a UI example with the creation of a cluster:
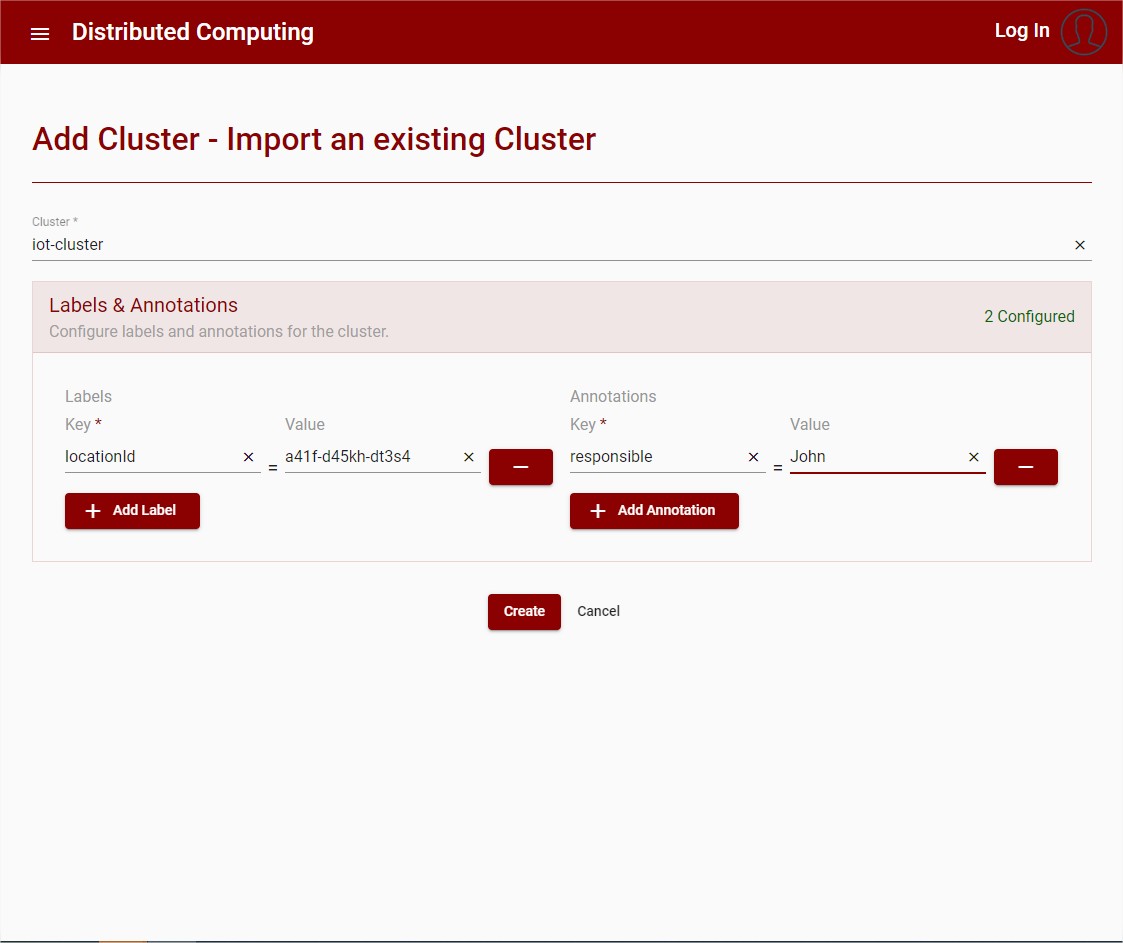
Figure 18: Create Cluster
After the Cluster is created, the user is redirected to the page where the commands to initiate the cluster are displayed, the user should use these commands to import it to Rancher.
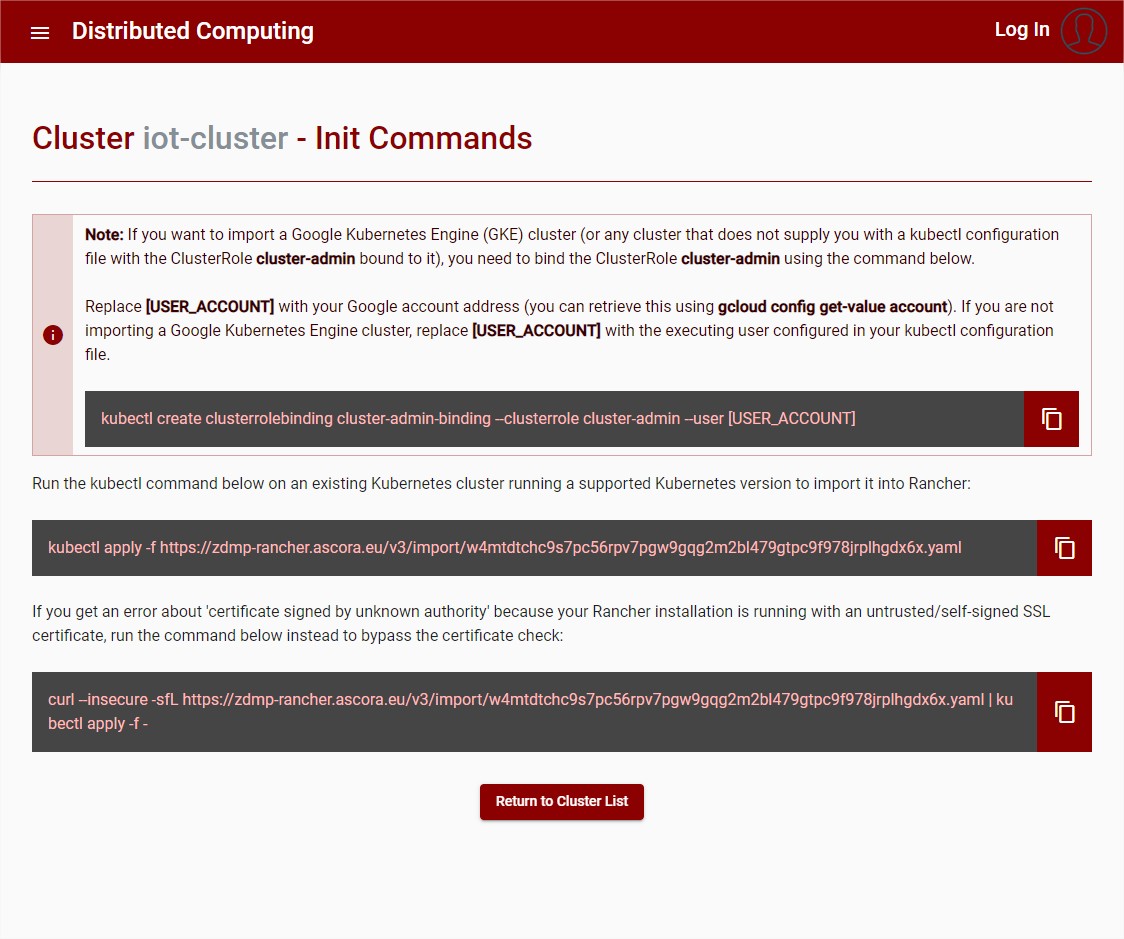
Figure 19: Cluster – Init commands
The user can then return to the cluster list where all clusters are listed.
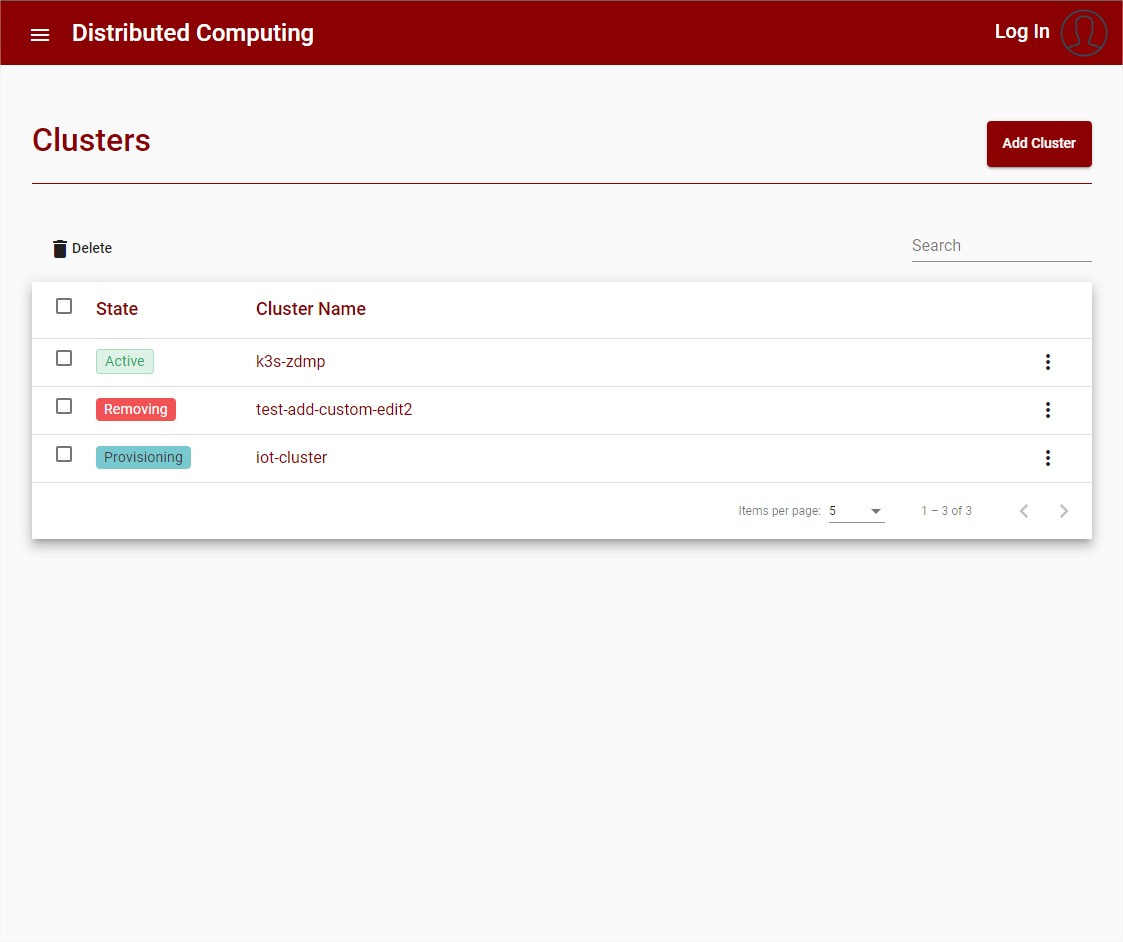
Figure 20: Cluster List
The user can deploy new services and applications using the function to import YAML.
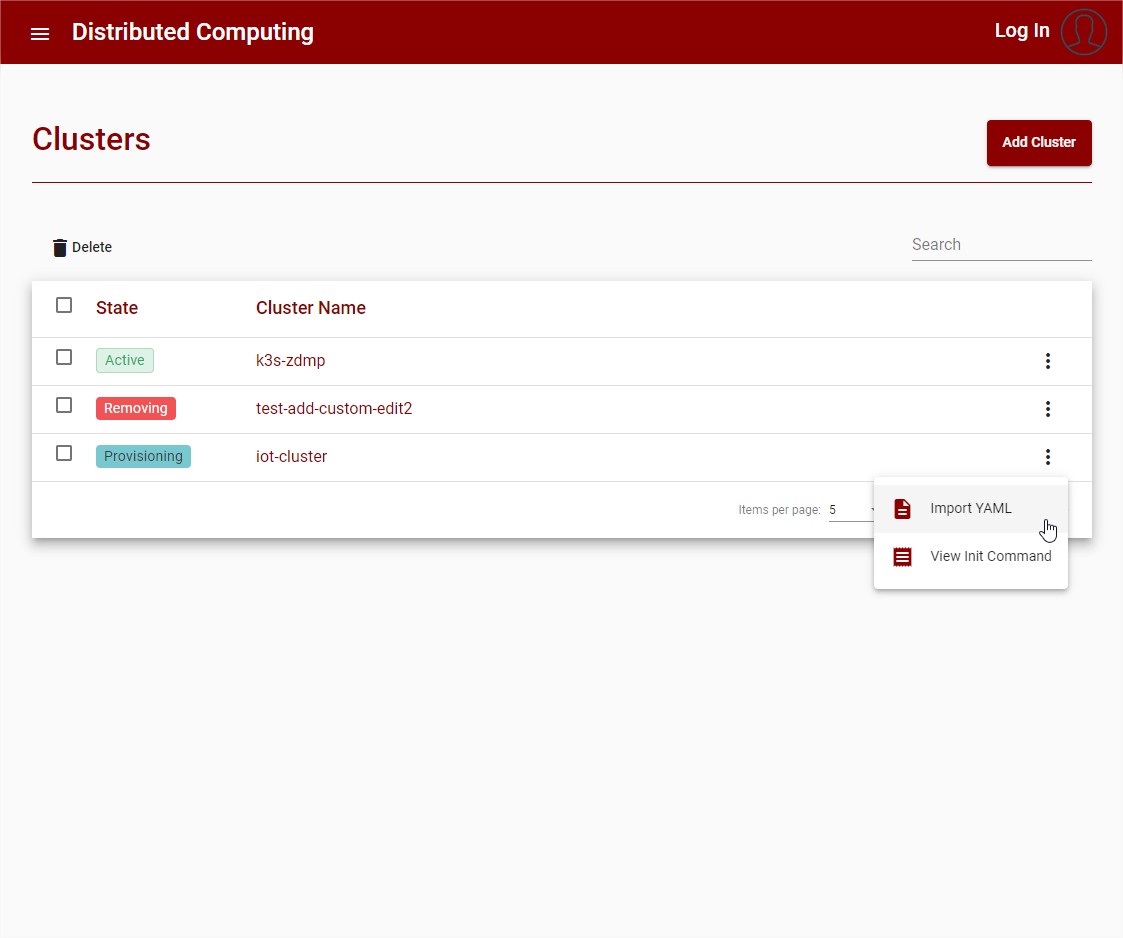
Figure 21: Cluster List – Import YAML
The user then needs to specify the deployment using a valid YAML notation. See the Kubernetes official documentation for more information. Follow an example with a nginx deployment:
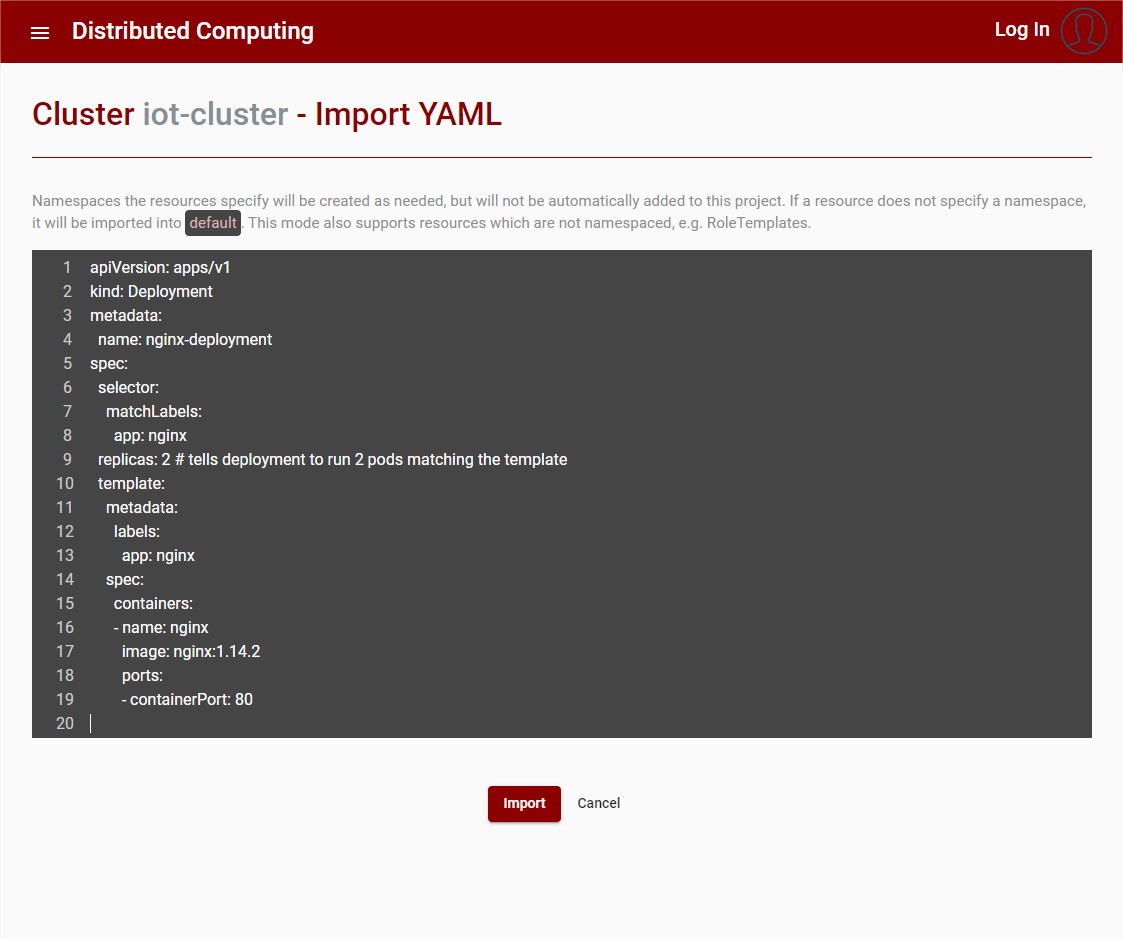
Figure 22: Cluster – Import YAML
Integration with the Security Designer
The integration with the security designer provides additional network information for the Location Resources Mapper, the Structure of the Location Resources are also upgraded to provide the additional information and display this data in a more human readable form. This feature is still in the planning phase and more information to be provided later.
Execute Distributed Task
To execute a distributed Task the user uses the YAML-Import function (for more information, see the Kubernetes official documentation). The following needs to be provided:
Task definition: A valid Kubernetes manifest YAML file must be provided. Everything that is needed for the task must be included, like the Deployment, Services or Volumes
Location: The location can be controlled with node labels. Custom node labels must be configured by the cluster administrator, for more information visit the Kubernetes official guide. It is also possible to use a node hostname as target label:
Edit YAML file: Everything within the YAML file can be adapted and changed like the container image or the location
Workloads: The imported tasks are displayed as workloads on an overview site with the URL to an endpoint if the task provided it.